

Getting started with the Intel Sapphire Rapids Xeon Max nodes
Introduction
SeaWulf now includes 94 new nodes featuring Intel’s Sapphire Rapids Xeon Max series CPUs (hereafter “SPR”). Each node contains 99 cores arrayed in 2 sockets and 256 GB of DDR5 memory. Importantly, each node also includes 128 GB of High Bandwidth Memory (HBM). HBM is expected to deliver substantial performance improvements for memory-bound applications; however, making effective use of HBM may require taking steps that may be unfamiliar for some users. This article will briefly explain how SeaWulf users can effectively utilize the SPR nodes for their jobs.
TL;DR
To see the list of avail modules, run "module avail" from the xeonmax or milan login nodes. The software built specifically for SPR will be found under /etc/modulefiles/xeonMax:

For the impatient, here is the recipe that we recommend using to ensure that your memory-bound MPI application ("a.out" in this example) uses HBM when possible:
module load numactl/2.0.16 mpirun --map-by numa numactl --preferred-many=8-15 ./a.out
(But please read on to understand more about how this works!)
Non-uniform memory access (NUMA)
Important to understanding the performance of not just the new SPR nodes, but essentially all modern computers, is the concept of non-uniform memory access (NUMA). Modern processors are so complex and big (even comprising multiple chips, aka sockets) that it is impossible to maintain a uniform access time from every core to every piece of memory --- i.e., the access time is non-uniform. Therefore, for best performance it is important to place the data that a thread of execution is using in memory close to the core on which the thread is running. Physical memory (literally the chips implementing the memory) is divided into NUMA regions and the operating system employs information about the physical layout of cores and memory to determine where to run threads and where to allocate memory.
Normally, all of this is hidden from you since performance differences are modest, however, on this architecture it is crucially important to be sure you are using the high-bandwidth memory closest to a running thread. The Linux command numactl is used to give information about the hardware (e.g., numactl -H to show how memory and/or cores are distributed across NUMA regions) and to control the mapping of threads to cores and which NUMA regions a thread should use (see below).
SPR node configuration
The following is a brief introduction to the configuration of SeaWulf’s SPR nodes. For a more detailed description, please refer to this excellent article.
In Flat mode with SNC4 clustering, both the DDR5 and HBM are available as main memory. In this configuration, each node’s memory is organized into 16 different NUMA regions. The following diagram illustrates the CPU and memory layout of SeaWulf’s SPR nodes with Flat mode configuration:
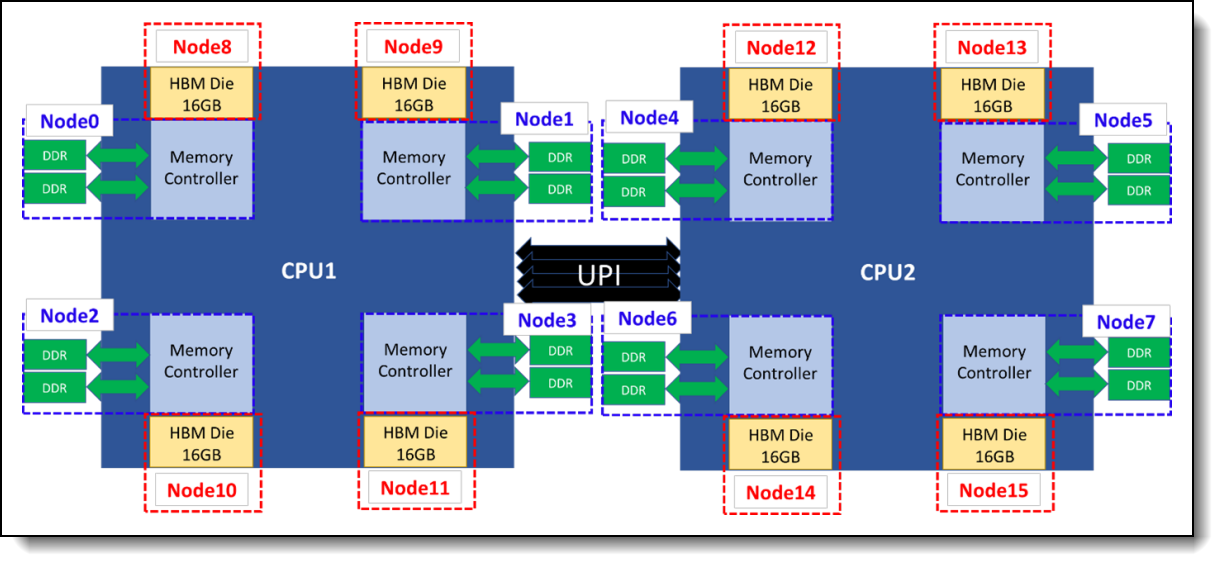
(source)
In this case, NUMA regions (also referred to as nodes in the diagram above) 0 through 7 each contain ~32 GB of DDR5 memory and are each assigned to 12 CPU cores. In contrast, NUMA regions 8 through 15 each contain 16 GB of HBM and are not assigned to any specific cores. This configuration is likely to deliver superior performance for memory-bound applications when users take steps to specifically assign processes to HBM NUMA regions over DDR5 memory (see “Getting the best performance…” below).
In contrast, in Cache mode, the HBM is configured as a level 4 Cache instead of being directly available as main memory for an application. Only DDR5 memory is available for use by applications. The main benefit of this configuration is its simplicity. No additional NUMA control steps need to be taken when running an application, so users whose application is either not very sensitive to memory bandwidth or is not easily mapped to the more complex SNC4 mode may find this a convenient and simplified option over the slightly more complicated procedure needed to use SNC4 mode.
At the time of writing (February, 2024), 90 SPR nodes on SeaWulf are configured in Flat mode with SNC4 cluster. In addition, 4 nodes have been configured in Cache mode with HBM used as a Level 4 cache. Each of these 4 nodes have also been configured with additional memory, totaling 1 TB of RAM per node.
Submitting jobs to the Sapphire Rapids partitions
In addition to the 94 SPR compute nodes, SeaWulf also now has a Sapphire Rapids login node called “xeonmax” that is directly accessible to users. You can access this node with the following:
ssh netid@xeonmax.seawulf.stonybrook.edu
From this login node, you can check the availability of modules (including software specifically built for the SPR nodes) with “module avail.”
To submit jobs to one or more of the Sapphire Rapids compute nodes, users have several partitions to choose from. The hbm-short-96core, hbm-long-96core, and hbm-extended-96core queues allow jobs to run for up to 4 hours, 48 hours, and 1 week, respectively. Likewise, the hbm-medium-96core and hbm-large-96core queues allow a single job to utilize up to 38 and 16 nodes in parallel, respectively. The hbm-1tb-long-96core partition should be used to access any of the 4 nodes with 1 TB memory configured in Cache mode.
Note also that jobs to these SPR partitions can also be submitted from the milan login nodes.
To find out more information about these and other SeaWulf queues, please see here. And for more specific information on how to submit jobs to the Slurm scheduler, please see here.
What compilers and MPI versions are available for the Sapphire Rapids nodes?
The default, system-level version of GCC on the Sapphire Rapids nodes is 11.3.1. Users can also load modules to gain access to compilers other than the system default. At the time of writing, the newest version of the GCC and Intel oneAPI suites available on SeaWulf can be accessed by loading the following modules:
gcc/13.2.0 intel/oneAPI/2025.0
Various implementations of MPI are also available on the Sapphire Rapids nodes, including Mvapich2, OpenMPI, and Intel MPI. To compile and run your application with Mvapich2 + GCC, we recommend the following module:
mvapich2/gcc13.2/2.3.7
For OpenMPI + GCC, we recommend:
openmpi/gcc13.2/4.1.6
For Intel MPI, first load the intel/oneAPI/2025.0 module, and then load the following:
compiler/latest mpi/latest
Getting the best performance for your application on Sapphire Rapids
To make effective use of HBM and get good performance for your application on the Sapphire Rapids nodes, we recommend the following steps:
1. Build your application on an SPR node with appropriate compiler flags, using one of the above compiler + MPI combinations (where applicable). Here are the flags we recommend:
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2. When using the nodes in Flat mode with SNC4, run your application with the latest version of Numactl to ensure that NUMA regions with HBM are preferentially selected over DDR5 memory. Numactl is a program that controls the memory placement policy of other programs, and using it is critical for making use of HBM. In general, we suggest the following:
# first load the latest version of numactl module load numactl/2.0.16 # use numactl to select HBM memory mpirun <any additional flags> numactl --preferred-many=8-15 ./a.out
(In the above, "< any additional flags>" refers to optional flags that can be added to your mpirun command.)
The above command will run your application (“a.out”) with MPI in such a way that HBM is utilized over DDR5 using any of the HBM NUMA regions (8-15). If your application can fit into 128 GB of memory per node, then only HBM will be utilized. If more than 128Gb of memory per node is required, then the application will fall back to using DDR5 as well to prevent out-of-memory errors.
For those using OpenMPI, we also recommend using the “--map-by” flag to balance the workload across different NUMA regions. For example:
mpirun --map-by numa numactl --preferred-many=8-15 ./a.out
Use of numactl to access HBM is not limited to MPI applications. For serial or threaded codes, you would want to run the following:
numactl --preferred-many=8-15 ./a.out
3. Test the performance! Our tests suggest that some applications may perform up to 2x better on SPR when using HBM instead of DDR5. But not all applications will experience this or any benefit from HBM. Thus, we encourage users who are new to this system to test their applications with and without HBM before running large jobs.
Example SPR Slurm job script
The following is an example Slurm job script that will run a job on 8 SPR nodes (Flat mode with SNC4) with 90 MPI processes per node. In this example, we use OpenMPI and Numactl to run our application with HBM.
#!/bin/bash #SBATCH --job-name=test-hello #SBATCH --output=test_mpi_hello.log #SBATCH --ntasks-per-node=96 #SBATCH --nodes=8 #SBATCH --time=00:05:00 #SBATCH -p hbm-short-96core # load the relevant modules module load openmpi/gcc12.1/ucx1.16.0/4.1.5 module load numactl/2.0.16 # execute your code with mpirun and numactl mpirun --map-by numa numactl --preferred-many=8-15 ./a.out
Additional examples
Additional codes and example jobs to help you get up to speed using the SPR nodes can be found in the following directory:
/gpfs/projects/samples/SPR_examples